Overview
Teaching: 20 min
Exercises: 20 minQuestions
How do you train a classifier?
Objectives
Understand that there are many different classifier methods.
Train a classifier on our dataset
Classification
Classification works with data that has labels, e.g. cat picture versus not cat picture, or healthy patient versus sick patient. It tries to learn which distinguishes these groups and make predictions of which group new data should be in.
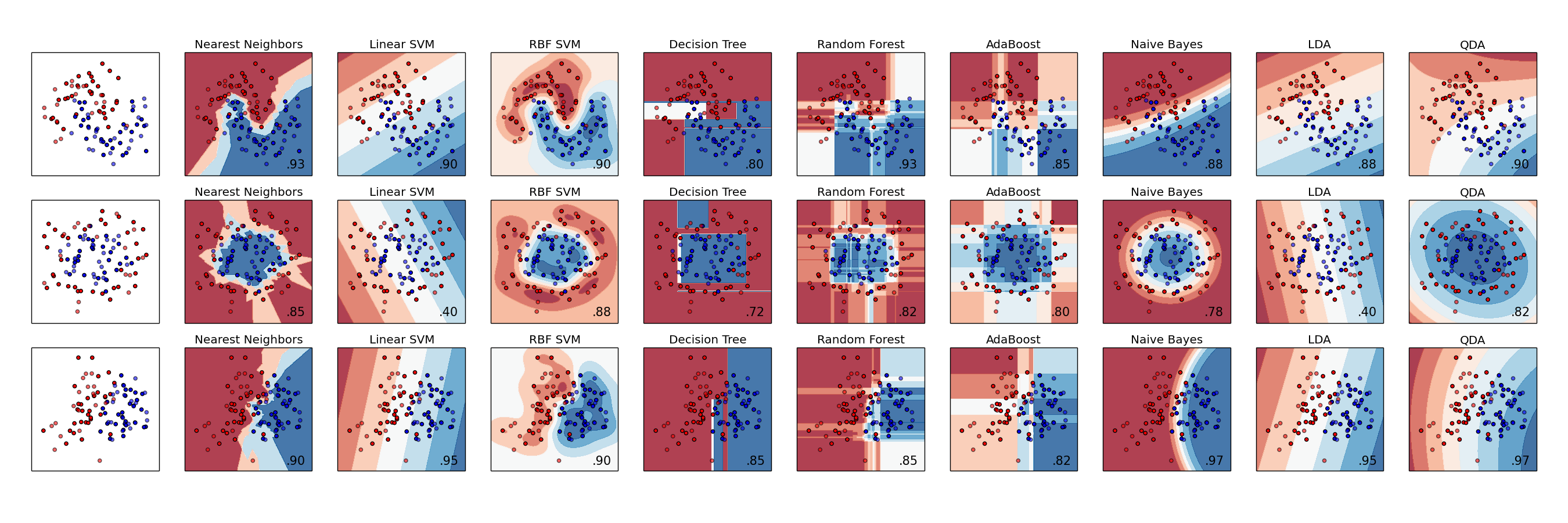
The figure below from the great scikit-learn documentation shows many different methods to it. The task is to try to distinguish between the red and blue data samples in the left boxes. The red and blue could represent healthy and sick patients. The X and Y axes are different features, so could represent two clinical features. Different methods find different boundaries to draw around the points to differentiate them. Any new data points would then be classified using these boundaries and different methods could give very different classifications.
Learning from training data
We can build a basic classifier using an IF statement. The code below iterates over the training data and classifies it based on a single column.
pred_train = []
for i in range(N_train):
if features_train[i,0] > 50:
pred_train.append(True)
else:
pred_train.append(False)
print(sum(pred_train),len(pred_train))
We want to know if our rule is a good rule. One metric of good classification is accuracy. It measures the number of classifications that we got correct. The code below calculates it as a percentage.
matching = 0
for i in range(N_train):
if pred_train[i] == target_train[i]:
matching += 1
train_accuracy = matching / N_train
print(train_accuracy)
Create a better rule
Take some time and try different rules (e.g. change the IF statement in the prediction loop.
Solution
There are many different rules that will get better performance on the training data. Below is one looking at height (column index 2).
pred_train = [] for i in range(N_train): if features_train[i,2] > 180: pred_train.append(True) else: pred_train.append(False) matching = 0 for i in range(N_train): if pred_train[i] == target_train[i]: matching += 1 train_accuracy = matching / N_train print(train_accuracy)
Checking with test data
Once we’ve decided on a method for classification, we should check if it holds for the test data which wasn’t use for creating the classifier. This way we can have some confidence that the classifier might would for new data that it has never seen before. First, let’s wrap up the code we created to calculate accuracy into a function so that we don’t have to rewrite it every time.
def calcAccuracy(target,pred):
matching = 0
for i in range(len(pred)):
if target[i] == pred[i]:
matching += 1
accuracy = matching / len(pred)
return accuracy
print(calcAccuracy(target_train,pred_train))
We can now do a classification of the test data using the same rule that we decided before. Change the code to whatever rule you decided gave the best performance. Does it give similar performance for the test data? Likely not. Here we have fit a method to the training data and picked the one with the best performance, which is what we want. But we will have (slightly) overfit the data and so won’t get as good performance on new unseen data (the test data).
pred_validation = []
for i in range(N_validation):
if features_validation[i,0] > 50:
pred_validation.append(True)
else:
pred_validation.append(False)
print(calcAccuracy(target_validation,pred_validation))
Scikit-learn classifiers
Scikit-learn comes with a huge set of prewritten classifiers that we can test out. The K Nearest Neighbors classifier is one of the simplest but is surprisingly powerful. For every prediction that it makes, it find the closest training samples and uses their classes to decide. It has one main parameter K, which is the number of neighbors to find. For K>1, it uses a voting system to decide which class to use. So for K=3, it finds three neighbors and if two are positives then it predicts positive. Let’s start with K=1.
We first have to import the specific classifier, in this case the KNeighborsClassifier. We then create an instance of it (clf) and supply the parameters to it: K=1.
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(1)
Next, we need to fit the classifier to the training data. We provide both the features (features_train) and the labels (target_train). This fit method is common for all scikit-learn classifiers.
clf.fit(features_train,target_train)
Then we can predict. We’ll predict first for the training data to see if it has learned anything from the training data.
pred_train = clf.predict(features_train)
print(calcAccuracy(target_train,pred_train))
The training performance certainly looks like amazing, but the validation performance is what matters for now.
pred_validation = clf.predict(features_validation)
print(calcAccuracy(target_validation,pred_validation))
That does seem great.
Remember class balance!
Remember that for this data set, the positive cases are in the minority. How would the accuracy looks if we created a stupid classifier that predicts everything as False? For this, we will use a list comprehension to create a list containing N_validation Falses.
pred_validation = [ False for _ in range(N_validation)]
print(calcAccuracy(target_validation,pred_validation))
Unfortunately, that gives performance that seems okay. But we know it’s not actually good. Accuracy is a metric that is not very helpful if there is a class imbalance.
A more advanced classifier
Try another scikit-learn classifier
Maybe the KNeighborsClassifier was too simple. Let’s explore the documentation of scikit-learn and choose another classifier. Try out a Random Forests. The bottom of each page in the scikit-learn API provides an example. So let’s just copy the example code in that defines the “clf” variable and try it with our existing code. Remember that you’ll need to put in the correct from/import line at the top too. It’ll be in the example code in the scikit-learn documentation.
Solution
Here’s the solution for using a LinearSVC as the classifier.
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(max_depth=2, random_state=0) clf.fit(features_train,target_train) pred_validation = clf.predict(features_validation) print(calcAccuracy(target_validation,pred_validation))
Key Points
You should learn a pattern using the training data and then see if the pattern holds with the testing data
Scikit-learn has many different classifiers. You may need to test a few to see which is best for your dataset